Shortly after OpenAI dropped DALL·E 3—its latest image generation model—in late 2023, I had a technological prognosis for society:
One day, there will be an app that generates you a unique, personalized piece of content on every swipe.
Soon™️
In line with existing infinitely-scrolling content feeds like Instagram Reels and TikTok, it will take into account various metrics to gauge your interest level, such as time spent viewing, reading or contributing comments, sharing links with friends, etc. It would incorporate everything it knew about you based on your browsing habits, searches, and engagement to generate a never-before-seen piece of content catered just for you. Like this one:

Obviously, the technology wasn’t there yet at the time, but I could see that it was coming. The developments of that year only served to confirm my theory: multi-modal models like GPT-4o came out that could incorporate text, audio and images all together; and video generation models like Pika and Sora could turn short bits of text into coherent streams of video up to a minute long.
The cost is still high: generating just a handful of images with DALL·E costs like a dollar, while video generating models get very expensive very quickly. The latency is also prohibitive: nobody is going to wait a full minute just for their content to load. However, these problems will go away as we make more progress in the field. So as time goes on, I’m still fully convinced this future is nigh upon us.
Guess I’ll do it myself
Today, after letting these ideas simmer for a long time and watching generative AI get better and better, I had a thought: why not just try making it? Unfortunately, there aren’t currently any (good) available generative video APIs. Pika, Sora, and Veo all either don’t have an API or require contacting their company. Fortunately, the architecture for a platform like this is basically identical for images.
With that in mind, an hour later I had a proof of concept running:1
The fully-armored knights sitting around a conference table (0:26 in) looking at chart of “quest performance metrics” honestly cracked me up; this has some potential.
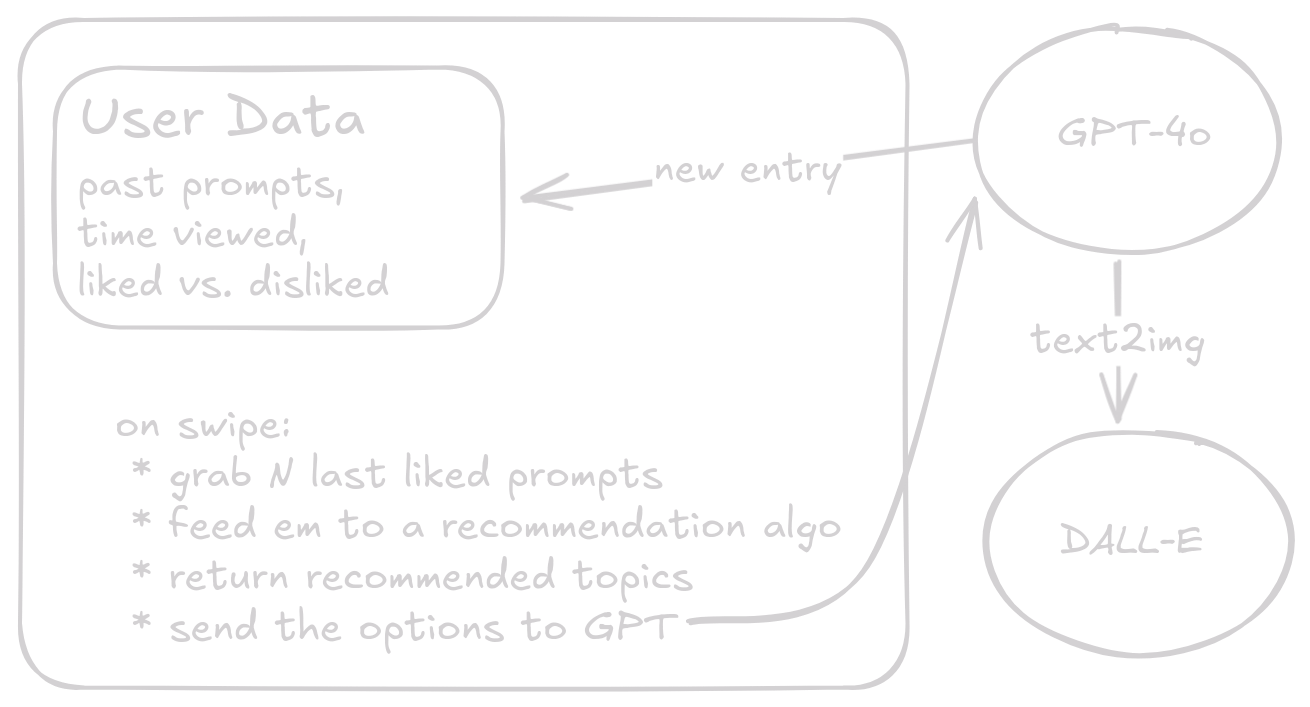
Architecture
Here’s the fun part: the entire front end was written by ChatGPT’s 4o model and so was like 80% of the backend, including the “recommendation” algorithm (well, sorta, as you’ll see). The architecture2 is fairly straightforward: track image prompts and use both “likes” and viewing time to gauge “engagement.” Occasionally, spit out a random image to prevent getting stuck on a topic.
The “seed” prompt is pretty straightforward and tries to succinctly capture the average piece of internet content:
Generate a random visual art prompt that could generate high social media engagement from a variety of users. It should be funny (like a situation or meme), relatable or nostalgic, or controversial.
Based on that, it seems like ChatGPT thinks cats are really engaging, which, granted, is fairly reflective of the Internet. After that, it uses a different prompt, followed by a series of topics that the recommendation algorithm spits out.
Recommendation Algorithm
Since I never sold my soul to any of the big corpos that have perfected the art of spying on you learning what you like, I went into this with no understanding of how recommendation algorithms worked. I had a rough idea of a simple approach and asked GPT-4o to implement it for me. The basic idea was something like this:
- Given the last
N“liked” prompts, turn ’em into numbers (floating point vectors) usingvec2word. - Do weighted k-means clustering on those vectors to find similarities across prompts, where weights are viewing time.
- Grab the average vector of each cluster.
- Turn that vector back into words and use that as a prompt guide.
GPT did its best but the prompts it produced were both deterministic and largely nonsensical. As it turns out, (4) is a preeeetty hard thing to do: vector embeddings are mostly a one-way operation unless you want to build and train a machine learning model to find related concepts and/or do a whole buncha work with WordNet. And ain’t nobody got time for that.
So what’s the lazy man’s solution? Well, why not just let GPT do the work for us?? I gave it the information about the last handful of prompts with high viewing times and asked it to find shared topics and suggest new prompts.
This actually worked way better than expected. For example, here’s a conversation I ripped out of the API logs. I bolded the terms in the AI’s new prompt that match terms from the given “liked” prompts:
Here are some prompts the user enjoyed:
- Dramatic seagull stealing an ice cream cone right out of the hand of a surprised beachgoer, cartoon style, exaggerated expressions, vibrant colors, humorous chaos, summer beach setting, relatable snack-hijacking moment.
- Cat sitting at a laptop with a headset, in a virtual meeting, surrounded by office supplies, frustrated expression, cluttered desk, playful meme vibe, relatable work-from-home chaos, soft pastel colors, cartoon style.
- Pigeon dressed as a tourist with a camera, snapping photos of famous landmarks, tiny hat and backpack, humorous travel mishaps, city skyline backdrop, lively and colorful street scene, exaggerated features, whimsical exploration theme.
Dog trying to take a selfie with a group of squirrels, using a selfie stick, chaos ensues as squirrels photobomb with silly poses and expressions, vibrant forest setting, cartoon style, bright colors, humorous wildlife interaction, playfully relatable technology mishap, exaggerated features.
Good enough for me! It’s a proof of concept, after all.
Follow-up improvements included incorporating dislikes so that it had an awareness of bad prompts: I noticed it getting a little hung up on certain themes if it ran long enough (like anthropomorphizing vegetables and animals, for some reason), so the constructive feedback was a valuable addition to keep things fresh. I also occasionally introduced “fresh” content into the feed (aka just don’t use the recommendation algorithm 33% of the time) to get new concepts into the mix.
Results
As you can see in the demo above, it does still lean heavily on cats but so does the Internet. In general, the content it generates is usually cute and playful (or, to use one of its favorite descriptors: “whimsical”) rather than the dank deep-fried brain rot I’m looking for on the Internet, but that’s just a matter of prompting and (getting decensored models). Humor might be the last human frontier, but it does spit out some pretty funny stuff occasionally, so watch out.
Once any of the big players drop a video generation model, it’ll be super easy to plug-and-play that into this proof-of-concept and see how it goes. Then, latency reduction and a better recommendation algorithm is all this thing needs. Well that and scaling to more than one user, but that’s obviously the easy part 😉
I stand by my prediction: give it a few years and an app like this will replace TikTok. Well, actually, a more realistic outcome is that TikTok will incorporate this into its feed itself.
Thanks for reading!
-
Please note that the video is heavily sped up to keep it interesting: a realistic delay between each image is more like 20 seconds. ↩︎
-
Shoutout to excalidraw for making diagrams absurdly easy to make. ↩︎